「ローカルLLMを導入したいが、実際に何を買えばいいのか分からない」
「本当に医療機関で使えるレベルなのか」
こうした問い合わせが増えています。
本記事では、2026年5月時点で買える代表的なハードウェア(NVIDIA DGX Spark、Apple Mac Studio)と、その上で動く主要なオープンウェイトモデル(gpt-oss-120b、Qwen3.5、Gemma 4)を整理します。
価格、メモリ要件、推論速度、そして医療現場での導入可否まで、閉域環境(外部ネットワークから切り離した環境)でAIを動かすために必要な情報をまとめました。
(GENSHI AI 代表 長嶋)
0. はじめに:ローカルLLMは「検討段階」から「選定段階」へ
前回の記事「ローカルLLMが医師国家試験で正答率89.7%」を公開して以降、医療機関や情報システム部門から多くの問い合わせをいただいています。
内容はほぼ共通しています。
- 「実際に何を買えばいいのか」
- 「いくらかかるのか」
- 「うちの環境でも動くのか」
「ローカルLLMで十分な性能が出るのか?」という段階はすでに通り過ぎました。
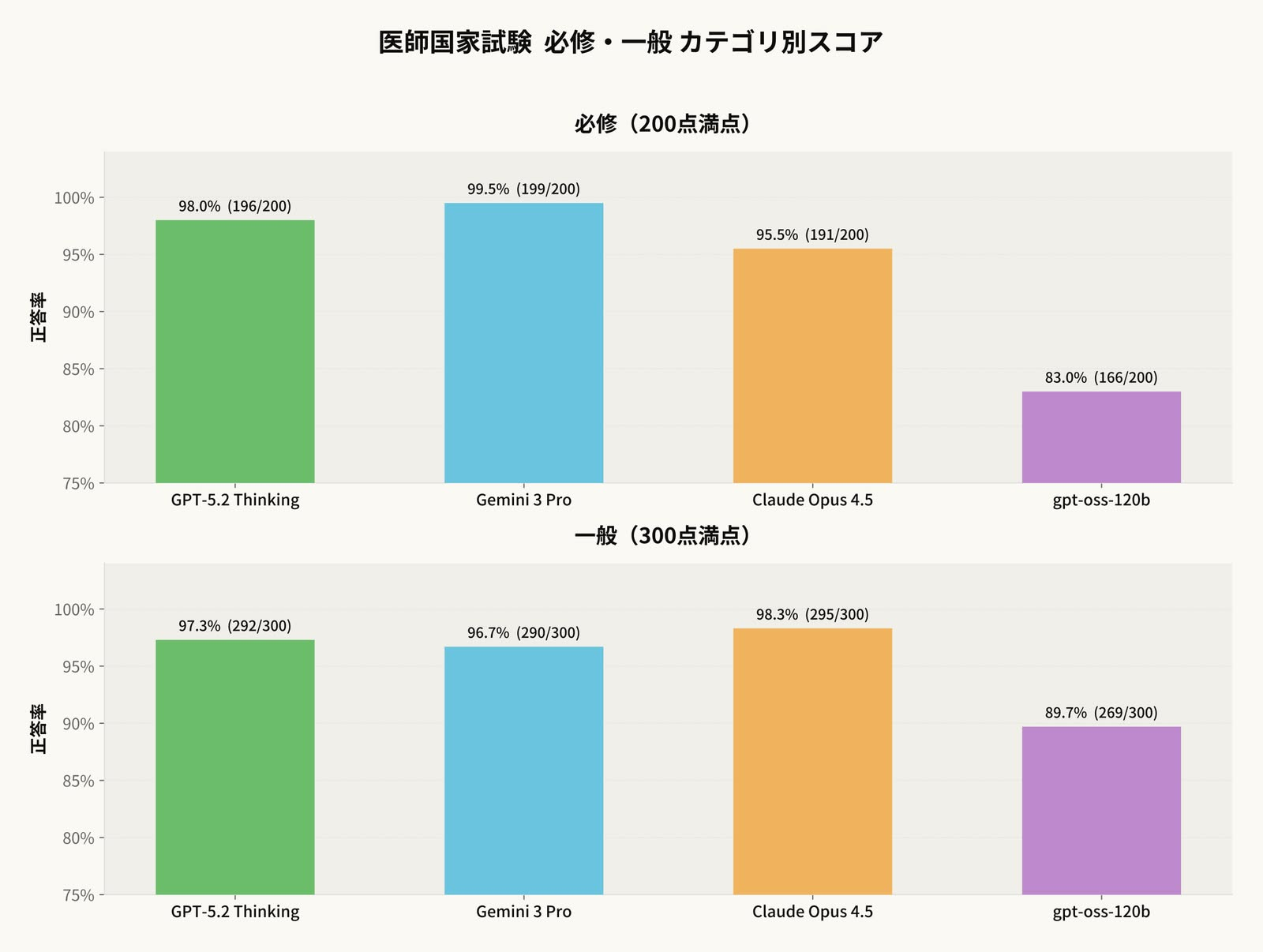
前回の検証で、gpt-oss-120bが医師国家試験の合格基準を超えたことは実証済みです。
残るのは「じゃあ具体的にどうすればいいのか」という問いだけです。
本記事は、2026年5月時点の最新情報をもとに、その問いに答える実践ガイドです。
1. 前提知識:なぜ「メモリ」がすべてを決めるのか
ローカルLLMの話をする前に、避けて通れない前提があります。
LLMを動かすには、モデルの中身(パラメータ)をすべてメモリ上に読み込む必要があるということです。
ChatGPTのようなクラウドサービスでは、この作業はOpenAIやGoogleのデータセンターが担っています。
しかしローカルLLMでは、手元のマシンのメモリそのものが制約になります。
ここがハードウェア選定の出発点です。
1.1 CPU、GPU、メモリ:それぞれの役割
まず、コンピュータの基本的な構成要素を整理します。
CPU(Central Processing Unit):コンピュータの「頭脳」。
ExcelやWebブラウジングなど、日常的な処理はCPUが担当します。
少数の処理単位(コア)で、複雑な処理を順番にこなすのが得意です。
GPU(Graphics Processing Unit):もとは画面描画用のプロセッサ。
数千〜数万の小さなコアを持ち、「同じ計算を大量のデータにいっせいに行う」ことに特化しています。
LLMの計算はまさに「大量の掛け算を並列でこなす」タスクで、GPUの方がCPUよりはるかに高速です。
メモリ(RAM):データを一時的に保持する領域。
CPUやGPUが処理するデータは、まずここに読み込まれる必要があります。
ポイントは、従来のコンピュータではCPUとGPUがそれぞれ別のメモリを持っているということです。

1.2 VRAM vs RAM:従来アーキテクチャの壁
一般的なデスクトップPCやサーバーでは、メモリが2つに分かれています。
- システムRAM(メインメモリ):CPU用。16GB〜128GBが一般的
- VRAM(ビデオメモリ):GPU専用のメモリ。GPUで使うデータはここに置く必要がある
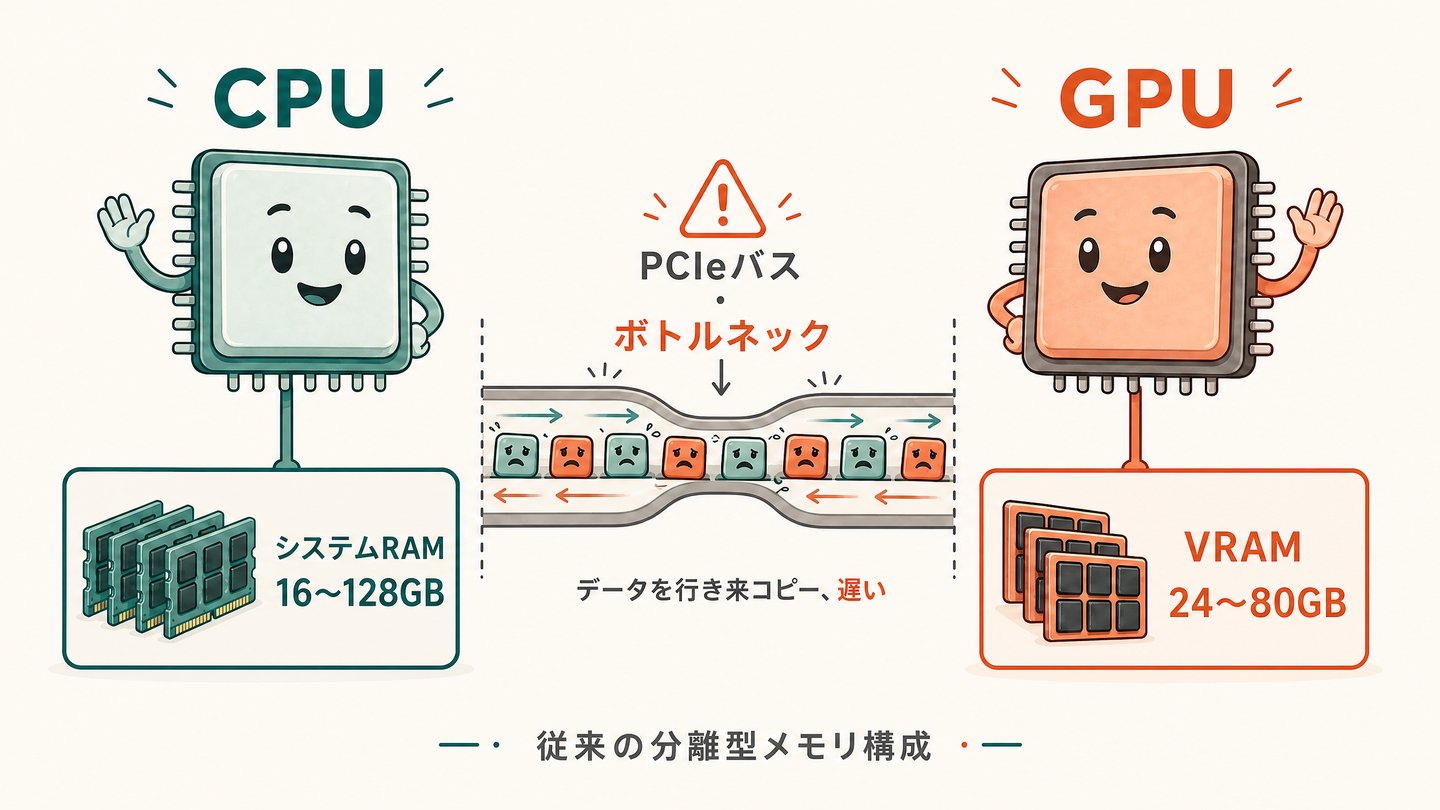
LLMの計算はGPUで行うため、モデルの中身はVRAMに載る必要があります。
しかし、一般的なGPUのVRAMは限られています。
| GPU | VRAM | 参考価格 |
|---|---|---|
| NVIDIA RTX 4090 | 24GB | 約30万円 |
| NVIDIA RTX 5090 | 32GB | 約40万円 |
| NVIDIA A100 | 80GB | 約250万円 |
| NVIDIA H100 | 80GB | 約500万円 |

では、LLMは実際にどれくらいのメモリを必要とするのでしょうか。
ここで「量子化」という技術が登場します。
1.3 量子化とは:モデルを「圧縮」して載せる技術
LLMのパラメータ(重み)は、通常BF16(モデルの数値精度を表す形式の一種、1パラメータあたり2バイト)で保存されています。
たとえばgpt-oss-120bは約1,170億パラメータ。
BF16のままだと、
1,170億 × 2バイト ≈ 234GB
必要になります。
これでは、先ほどの表のどのGPUにも載りません。
そこで登場するのが「量子化」です。
パラメータの精度を意図的に下げて、モデル全体のサイズを大幅に縮める技術です。
イメージはJPEGの画質設定に近いです。
画質を少し落とせばファイルサイズが劇的に小さくなるように、量子化も精度をわずかに犠牲にして、必要なメモリ量を半分〜4分の1以下に削減できます。
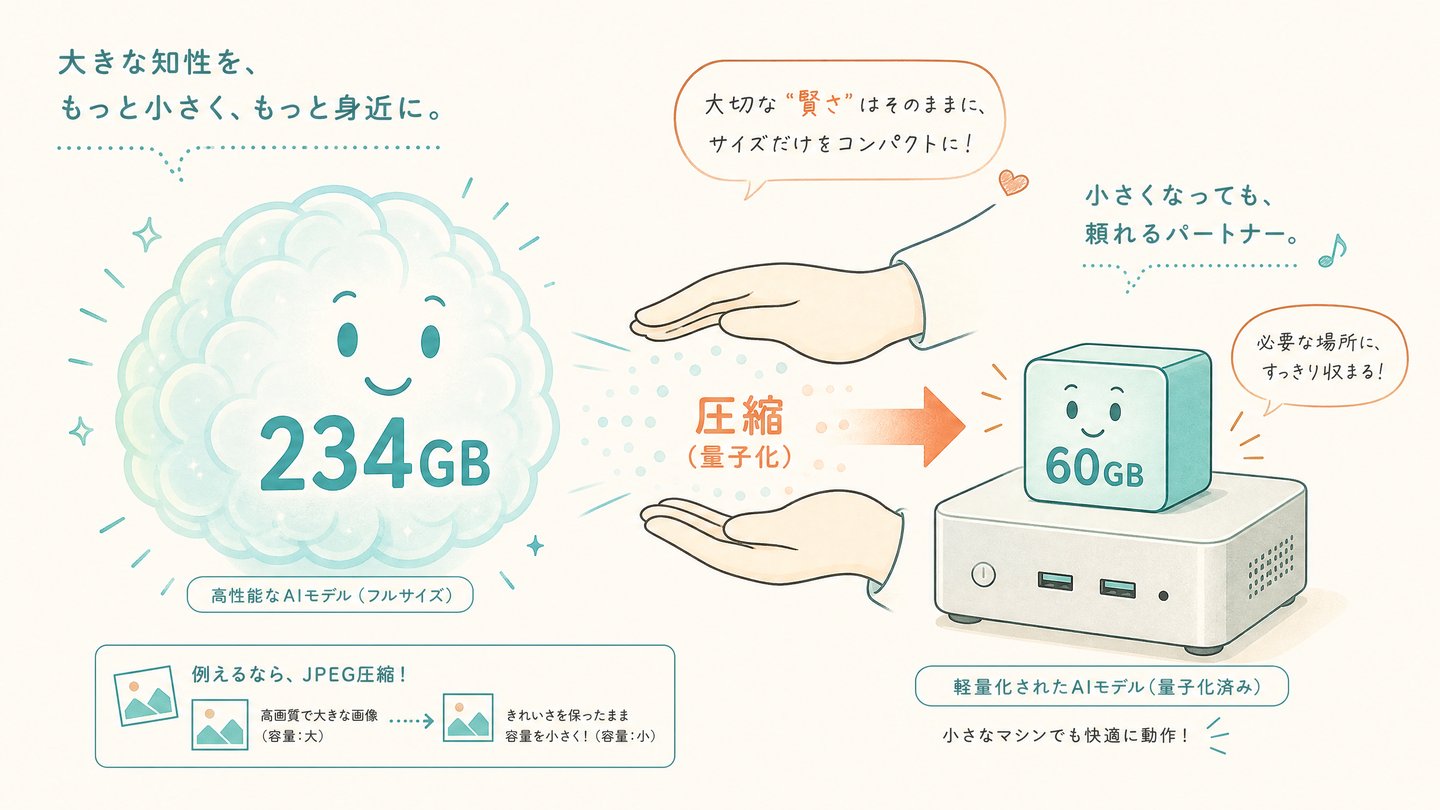
主な量子化レベルは次の通りです。
| 量子化 | 1パラメータあたり | サイズ(BF16比) | 精度への影響 | 用途 |
|---|---|---|---|---|
| BF16(非量子化) | 16bit(2バイト) | 100%(基準) | 劣化なし | 精度最優先の研究用途 |
| Q8(8bit量子化) | 8bit(1バイト) | 約50% | ほぼ劣化なし | 精度と効率のバランス |
| Q4(4bit量子化) | 4bit(0.5バイト) | 約25% | わずかに劣化 | 実用のスタンダード |
| Q2(2bit量子化) | 2bit(0.25バイト) | 約12.5% | 明確に劣化 | 極限の軽量化(非推奨) |
ローカルLLMではQ4(4bit量子化)が標準的に使われます。
ベンチマーク上の精度低下はごくわずかで、体感ではBF16との差はほとんど感じません。
前回の医師国家試験検証でも、gpt-oss-120bのQ4モデルで合格基準を超える成績を達成しています。
1.4 各モデルの必要メモリ量:結局何GBいるのか
ハードウェア選定で最も重要な判断材料は、「どのモデルが何GBのメモリを必要とするか」です。
本記事で扱う主要モデルを一覧にします。
※下記はモデルの重みのみの概算です。
実際の推論時にはKVキャッシュ(直前までの文脈を覚えておくメモリ領域)やランタイムのオーバーヘッドが加算されるため、実用上は表の値の1.2〜1.5倍程度のメモリを見ておく必要があります。
| モデル | 総パラメータ | BF16(非量子化) | Q8 | Q4 | 128GBで動くか | 256GBで動くか |
|---|---|---|---|---|---|---|
| gpt-oss-120b | 117B | ~234GB | ~117GB | ~60GB | ○ | ◎ |
| Qwen3.5-27B | 27B | ~54GB | ~27GB | ~16GB | ◎ | ◎ |
| Qwen3.5-35B-A3B | 35B | ~70GB | ~35GB | ~20GB | ◎ | ◎ |
| Qwen3.5-397B-A17B | 397B | ~794GB | ~397GB | ~200GB | × | ○ |
| Gemma 4 31B | 31B | ~62GB | ~31GB | ~18GB | ◎ | ◎ |
表から見えてくるポイントを整理します。
Q4量子化なら、ほとんどのモデルが128GBマシンに載ります。
100B級のgpt-oss-120b(~60GB)でも、Q4にすれば128GBの統合メモリに収まります。
ただし余裕は少なく、長いコンテキストや複数モデルの同時稼働は厳しくなります。
256GBあれば、ほぼすべてのモデルを快適に動かせます。
Qwen3.5-397B-A17B(~200GB)のようなフラッグシップ級のモデルも、256GBのMac Studioなら単体で動作可能です。
BF16(非量子化)は、現実的にはほぼ選択肢になりません。
27B以上のモデルをBF16で動かすには128GB以上が必要で、120B級になると234GB。
デスクトップの容量を超えてしまいます。
Q4で十分な性能が出る以上、BF16にこだわる理由は研究用途以外ほぼありません。
要するに、「メモリに載るかどうか」は「モデルサイズ × 量子化レベル ≤ マシンのメモリ容量」という単純な掛け算です。Q4を前提にすれば、128GBマシンで100B級、256GBマシンで400B級まで対応できます。
ここまでをまとめると、ローカルLLMを動かすマシンに必要な条件は3つです。
- 大容量の統合メモリ(128GB以上、理想は256GB)
- 高速なメモリ帯域幅(推論速度に直結)
- GPUの演算能力(並列計算のため)
これら3つの条件をデスクトップマシンで満たす鍵が「ユニファイドメモリ」です。
Macでは2022年のM1 Ultra以降、大容量ユニファイドメモリ搭載機が拡充されてきました。
NVIDIA側でも2026年のDGX Sparkで採用され、選択肢が広がっています。
1.5 ユニファイドメモリ(統合メモリ):ゲームチェンジャー
この壁を解消するのが、「ユニファイドメモリ(統合メモリ)」と呼ばれる仕組みです。

ユニファイドメモリでは、CPUとGPUが同じメモリを共有します。
「VRAM」と「システムRAM」の区別がなくなり、搭載メモリの全容量をGPUの計算に使えます。
従来は、GPUが処理するためにシステムRAMからVRAMへデータをコピーする必要がありました。
このコピーが帯域のボトルネックでした。
ユニファイドメモリではコピーそのものが不要になります。
現在、ユニファイドメモリを採用しているプラットフォームは2つあります。
Apple Silicon(M3 Ultraなど):CPU・GPU・Neural Engineが同じチップ上に統合され、LPDDR5(低消費電力の高速メモリ規格)を共有します。
Mac Studio M3 Ultraでは最大256GBの統合メモリを搭載でき、メモリの読み書き速度(帯域幅)は819 GB/sに達します。
NVIDIA GB10(DGX Spark):Apple Siliconと同様に、Grace CPUとBlackwell GPUを単一のSoCパッケージに統合し、128GBのLPDDR5Xメモリを共有します(チップ間の結線にはNVLink-C2Cと呼ばれるパッケージ内インターコネクトを採用)。
メモリ帯域幅は273 GB/s。
Apple Siliconほど速くはありませんが、従来型のアーキテクチャと比べるとはるかに高速です。
1.6 メモリ帯域幅:「載る」と「速い」は別の話
もう一つ重要な概念があります。「メモリ帯域幅」です。
LLMはテキストを生成する際、1文字(厳密には1トークン)出すたびにモデルの全パラメータをメモリから読み出します。
つまり、生成速度は「メモリからどれくらい速くデータを読み出せるか」にほぼ比例します。
これがメモリ帯域幅です。
具体的に計算してみます。
gpt-oss-120bのQ4モデル(約60GB)の場合:
- Mac Studio M3 Ultra(819 GB/s):819 ÷ 60 ≈ 13.6 → 理論上の上限は約13 tok/s
- DGX Spark(273 GB/s):273 ÷ 60 ≈ 4.5 → 理論上の上限は約4〜5 tok/s
実際にはオーバーヘッドがあるため理論値には届きませんが、帯域幅の比がそのまま速度差に直結することが分かります。
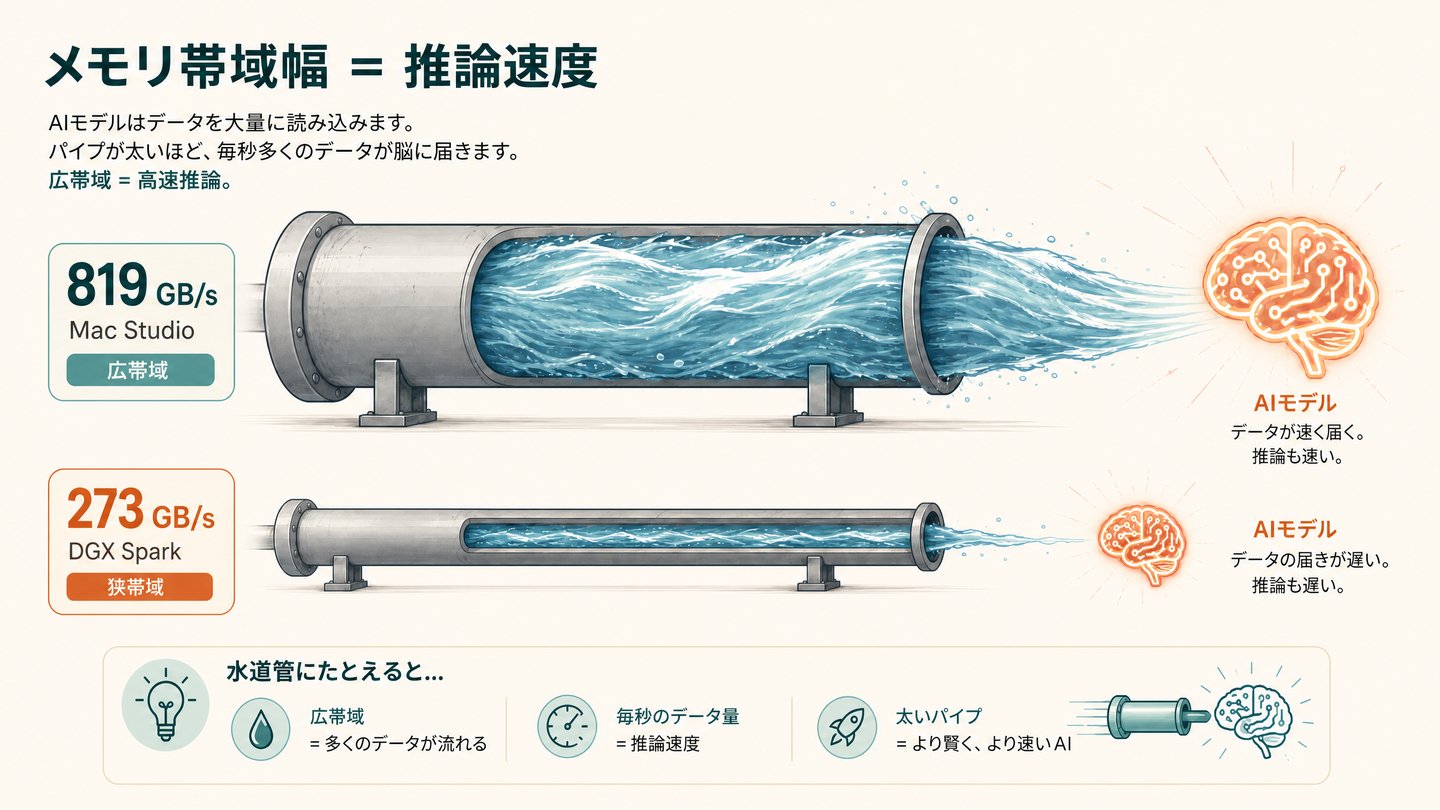
「メモリに載る」ことと「速く動く」ことは別の問題です。メモリ容量は「動くかどうか」を決め、メモリ帯域幅は「どれだけ速く動くか」を決めます。
この前提のうえで、具体的なハードウェアを見ていきます。
2. ハードウェア:何を買えばいいのか
2026年4月現在、ローカルLLM用途に適したデスクトップマシンは、大きく分けて2つあります。
2.1 NVIDIA DGX Spark(およびGB10搭載OEMモデル)
DGX Sparkは、NVIDIAが提供するデスクトップ型AIコンピュータです。
専用チップ「GB10 Grace Blackwell Superchip」を搭載しています。

| 項目 | スペック |
|---|---|
| チップ | NVIDIA GB10 Grace Blackwell Superchip |
| CPU | 20コアARM(Cortex-X925 × 10 + Cortex-A725 × 10) |
| GPU | Blackwell GPU(CUDA 6,144コア、第5世代Tensorコア) |
| メモリ | 128GB LPDDR5X(統合メモリ) |
| メモリ帯域幅 | 273 GB/s |
| AI演算性能 | 最大1 PFLOP(FP4、スパース) |
| ストレージ | 4TB NVMe SSD(Founders Edition) |
| 消費電力 | 約100W(実測)/ アダプタ定格240W |
| 筐体サイズ | 150mm × 150mm × 50.5mm(重量1.2kg) |
| OS | DGX OS(Ubuntu 24.04ベース) |
| 価格(US) | $4,699(Founders Edition、2026年2月改定) |
| 価格(日本) | 約65〜70万円(販売店による) |
2026年2月、メモリ供給逼迫を背景にFounders Editionの価格が$3,999から$4,699に引き上げられました。
日本国内ではNTTPC(640,000円〜)、アプライドネット(MSI OEM 658,000円〜)、リョーサン菱洋、ELSA、ジーデップ・アドバンスなどから購入可能です。
最大の魅力は、128GBの統合メモリをデスクトップサイズで実現している点です。
一般的なGPUのVRAM容量はRTX 4090で24GB、H100でも80GBが上限ですが、DGX Sparkはその128GBをCPUとGPUで共有し、大規模モデルを丸ごと読み込めます。
さらにAI開発で広く使われている標準的なソフトウェア環境(PyTorch・vLLM・TensorRT-LLMなど、NVIDIA系のツール群)がそのまま動くのもポイントです。
GB10搭載OEMモデル
NVIDIAはGB10チップをOEMパートナーにも提供しており、各社から同等スペックのマシンが発売されています。
| メーカー | モデル名 | 価格(US参考) | ストレージ | 特徴 |
|---|---|---|---|---|
| NVIDIA | DGX Spark Founders Edition | $4,699 | 4TB NVMe Gen5 | 基準モデル。モデルロード速度最速 |
| Dell | Pro Max GB10 | $3,699 | 2TB | エンタープライズ向け管理機能 |
| ASUS | Ascent GX10 | $3,099 | 1TB | 最安。ただし排熱に注意 |
| MSI | EdgeXpert | $2,999 | 1TB | 最安クラス。筐体品質は価格相応 |
すべて同じGB10チップを搭載しているため、推論性能は同一です。
差が出るのは筐体の排熱設計、ストレージ速度、管理機能といった周辺要素です。
注意点:DGX Sparkのメモリ帯域幅は273 GB/s。これは大規模モデルを「読み込む」ことはできても、「速く推論する」のには制約があるということです。70Bモデルの場合、FP8(8bit浮動小数点形式)で2〜3 tok/s程度。後述のMac Studioとの比較において、この点は重要な判断材料になります。
2台連結による拡張
DGX SparkにはConnectX-7 200Gbps NIC(高速ネットワーク機能)が搭載されており、2台をケーブル直結することで256GBの統合メモリプールを構成できます。
これにより、最大4,050億パラメータのモデルの推論が可能になります。
スイッチ不要、ケーブル1本で接続できる手軽さも魅力です。

2.2 Apple Mac Studio(M3 Ultra)
Mac Studioは、Appleのユニファイドメモリ機構を活かしたデスクトップマシンです。
ローカルLLM用途では、M3 Ultraチップ搭載・256GB構成が主力の選択肢になります。
Apple独自のAI実行環境(llama.cppやMLXといったApple Silicon向けに最適化されたツール)を使うのが基本です。

| 項目 | スペック(M3 Ultra / 256GB構成) |
|---|---|
| チップ | Apple M3 Ultra |
| CPU | 28コア(高性能20 + 高効率8)※32コアCPU/80コアGPU構成も選択可 |
| GPU | 60コア(または80コア) |
| Neural Engine | 32コア |
| メモリ | 256GB ユニファイドメモリ |
| メモリ帯域幅 | 819 GB/s |
| ストレージ | 1TB〜(CTO最大16TB) |
| 筐体サイズ | 197mm × 197mm × 94mm |
| 価格(US) | 約$5,999〜(96GB→256GBへのアップグレード込み) |
| 価格(日本) | 約85〜90万円(256GB構成) |
Mac StudioがDGX Sparkに対して持つ最大の強みは、メモリ帯域幅の差です。
819 GB/s対273 GB/sで、約3倍。
LLMの推論速度はメモリ帯域幅にほぼ比例するため、同じモデルを動かした場合、Mac Studioの方が生成速度が大幅に上回ります。
さらに、256GBのメモリ容量はDGX Sparkの128GBの2倍。
gpt-oss-120bのQ4モデル(約60GB)はもちろん、Qwen3.5-397B-A17Bのような超大規模モデルの量子化版も単体で動作させることができます。
ただし注意点があります。
2026年3月、AppleはDRAMの世界的な供給逼迫を受けて512GBメモリ構成を廃止し、256GBオプションの価格を$400引き上げました。
2026年4月現在、256GBモデルの納期は5〜6週間以上に延びており、入手性が低下しています。
(2026年5月時点では128GB・256GB構成の新規受付が停止しており、新品確保には中古や法人ルートでの調達が必要になる可能性があります)
2.3 ハードウェア比較:どちらを選ぶべきか
| 比較項目 | DGX Spark(128GB) | Mac Studio M3 Ultra(256GB) |
|---|---|---|
| メモリ容量 | 128GB | 256GB |
| メモリ帯域幅 | 273 GB/s | 819 GB/s |
| 推論速度(70B級・8bit目安) | 2〜3 tok/s | 8〜10 tok/s |
| 2台連結 | ○(256GBプール) | × |
| 価格帯 | 約65〜70万円 | 約85〜90万円 |
| 納期 | 在庫状況による | 5〜6週間以上(256GB) |
| 対応ソフトウェア | NVIDIA系の標準ツール群(PyTorch・vLLMなど) | Apple独自環境(llama.cpp・MLX) |
整理すると、選定の判断基準は次の通りです。
DGX Sparkが向くケース
- NVIDIA系のAI開発ツール群(PyTorch・vLLM・TensorRT-LLMなど)を活用したい
- NVIDIA AI Enterpriseなど企業サポートが必要
- 将来的に2台連結で拡張したい
- 128GBで収まるモデルサイズを使う
- 予算を抑えたい(OEMモデルなら約50万円台から)
Mac Studioが向くケース
- 生成速度を重視する(帯域幅3倍の差)
- 256GBの大容量メモリが必要(大規模モデルや複数モデル同時稼働)
- macOSの運用管理に慣れている
- llama.cppやMLXでの運用に問題がない
前回の医師国家試験検証では、Mac Studio(M3 Ultra / 256GB)を使用しました。
gpt-oss-120bのQ4モデルを快適な速度で動かすには、帯域幅の余裕があるMac Studioに軍配が上がります。
一方、NVIDIAのソフトウェアスタックを前提としたシステム構築では、DGX Sparkの方がスムーズです。
3. モデル:何を動かせるのか
2026年4月現在、ローカルLLM用途で注目すべきオープンウェイトモデルは次の3系統です。
いずれもApache 2.0ライセンスで、商用利用を含め自由に利用可能です。
3.1 gpt-oss-120b(OpenAI)
前回記事で医師国家試験の検証に使用したモデルです。

| 項目 | 仕様 |
|---|---|
| 総パラメータ数 | 1,170億(117B) |
| アクティブパラメータ数 | 51億(5.1B)/トークン |
| アーキテクチャ | Mixture of Experts(MoE:必要な部分だけ動かす効率型の構造)、128エキスパート、4アクティブ |
| コンテキスト長 | 128Kトークン |
| モダリティ | テキストのみ |
| 量子化 | MXFP4ネイティブ対応(約60GB) |
| ライセンス | Apache 2.0 |
| リリース | 2025年8月 |
特長はヘルスケア領域での高い性能です。
OpenAIが公開しているHealthBenchでは、o3にほぼ匹敵するスコアを記録しています。
MXFP4という量子化形式に最初から対応しているため、DGX Sparkの128GBメモリに収まり、Mac Studioの256GBであれば余裕を持って動作します。
制約:テキスト専用モデルのため、画像入力には対応していません。
CT画像の読影支援など画像を扱う業務にはそのまま適用できませんが、カルテのテキスト処理、文書ドラフト作成、院内Q&Aなどテキスト中心の業務では十分な性能を発揮します。
3.2 Qwen3.5シリーズ(Alibaba / Qwen Team)
2026年2月にリリースされたQwen3.5は、テキスト・画像・動画を一つのモデルで扱えるマルチモーダルモデル(複数の入力形式に対応するモデル)です。

| モデル | 総パラメータ | アクティブパラメータ | アーキテクチャ | コンテキスト長 | 特徴 |
|---|---|---|---|---|---|
| Qwen3.5-27B | 27B | 27B(Dense) | Dense + GDN | 262K(最大1M) | SWE-bench Verified 72.4%。GPT-5 miniに匹敵 |
| Qwen3.5-35B-A3B | 35B | 3B | MoE + GDN | 262K(最大1M) | 前世代235B-A22Bを超える効率 |
| Qwen3.5-397B-A17B | 397B | 17B | MoE + GDN | 262K(最大1M) | フラッグシップ。フロンティア級 |
Qwen3.5の革新は、Gated Delta Networks(GDN)とMoE(必要な部分だけ動かす効率型の構造)のハイブリッド設計にあります。
従来のTransformerが抱えていたメモリ消費の重さを大幅に削減し、長いコンテキストでも省メモリで高速に動作します。
医療現場での活用を考えると、特に注目すべきは次の2モデルです。
Qwen3.5-35B-A3B:総パラメータ35Bに対しアクティブはわずか3B。
DGX Sparkでも快適に動く軽量さでありながら、前世代の235Bフラッグシップを上回る性能を持ちます。
画像入力にも対応しており、CT画像や検査結果を含む業務にも適用できます。
Q4で約20GB前後のメモリで動作するため、DGX SparkでもMac Studioでも余裕です。
Qwen3.5-27B:Dense(非MoE)モデルで、全27Bパラメータが常にアクティブ。
MoEモデルと比べて推論の安定性が高く、SWE-bench Verified 72.4%というコーディング性能はGPT-5 miniに並びます。
マルチモーダル対応。
Q4で約16GB、BF16で約54GBのメモリが必要です。
※2026年4月22日には後継のQwen3.6シリーズが公開され、27B帯では上位互換となるモデルも登場しています。最新性能を重視する場合はQwen3.6系の検討余地があります。本記事では検証実績のあるQwen3.5を前提に解説します。
3.3 Gemma 4シリーズ(Google DeepMind)
2026年4月2日にリリースされたGemma 4は、Gemini 3の研究基盤から生まれたGoogleのオープンウェイトモデルです。
Gemmaシリーズとして初めてApache 2.0ライセンスで公開されました。

| 項目 | 仕様 |
|---|---|
| 総パラメータ | 31B(Denseモデル) |
| コンテキスト長 | 256Kトークン |
| モダリティ | テキスト、画像、動画 |
| 主要ベンチマーク | MMLU Pro 85.2% / AIME 2026 89.2% |
| ライセンス | Apache 2.0 |
| リリース | 2026年4月2日 |
Gemma 4 31Bの真価はパラメータあたりの知能密度にあります。
MMLU Proで85.2%、AIME 2026で89.2%と、そのサイズからは信じがたい推論性能を発揮し、Arena AIのテキストリーダーボードでオープンモデル3位にランクインしています。
医療現場でのポイント:Gemma 4はOCR(手書き文字認識を含む)、チャート解釈、文書パーシング(構造の解釈)、UIの構造理解といった視覚タスクに強みがあります。
紙ベースの医療文書のデジタル化や、検査結果レポートの構造化処理で威力を発揮します。
4. マシン × モデルの組み合わせ:何がどう動くか
ここが本記事の核心です。
各マシンで、各モデルがどの程度の実用性で動作するかを整理します。
4.1 DGX Spark(128GB)で動くモデル
| モデル | 量子化 | メモリ使用量(目安) | 動作可否 | 推論速度(目安) |
|---|---|---|---|---|
| gpt-oss-120b | MXFP4 | ~60GB | ○ | 5〜8 tok/s |
| Qwen3.5-27B | Q4 | ~16GB | ◎ | 20〜30 tok/s |
| Qwen3.5-35B-A3B | Q4 | ~20GB | ◎ | 30+ tok/s |
| Qwen3.5-397B-A17B | Q4 | ~200GB | × | 2台連結が必要 |
| Gemma 4 31B | Q4 | ~20GB | ◎ | 20〜25 tok/s |
※推論速度はワークロードやコンテキスト長によって大きく変動します。
上記は短い入力での目安です。
4.2 Mac Studio M3 Ultra(256GB)で動くモデル
| モデル | 量子化 | メモリ使用量(目安) | 動作可否 | 推論速度(目安) |
|---|---|---|---|---|
| gpt-oss-120b | Q4 | ~60GB | ◎ | 15〜20 tok/s |
| Qwen3.5-27B | BF16 | ~54GB | ◎ | 15〜20 tok/s |
| Qwen3.5-35B-A3B | Q4 | ~20GB | ◎ | 60+ tok/s |
| Qwen3.5-397B-A17B | Q4 | ~200GB | ○ | 3〜5 tok/s |
| Gemma 4 31B | BF16 | ~62GB | ◎ | 12〜15 tok/s |
Mac Studioの帯域幅819 GB/sの恩恵により、同じモデルでもDGX Sparkの2〜3倍の推論速度が期待できます。
特にgpt-oss-120bのような大規模モデルでは、この差が体感に大きく影響します。
5. 医療機関での導入:実際どうなのか

5.1 閉域環境で本当に動くのか
動きます。
ローカルLLMは、定義上、すべての処理が手元のマシン上で完結します。
モデルファイルを事前にダウンロード(またはUSBメディアなどでオフライン搬入)し、マシンに読み込めば、以降はインターネット接続は不要です。
電源とマシン本体さえあれば動きます。
Wi-Fi、イーサネット、一切のネットワーク接続を物理的に切断した状態でも、問題なく推論を実行できます。
前回の医師国家試験検証も、オフラインで実施しています。
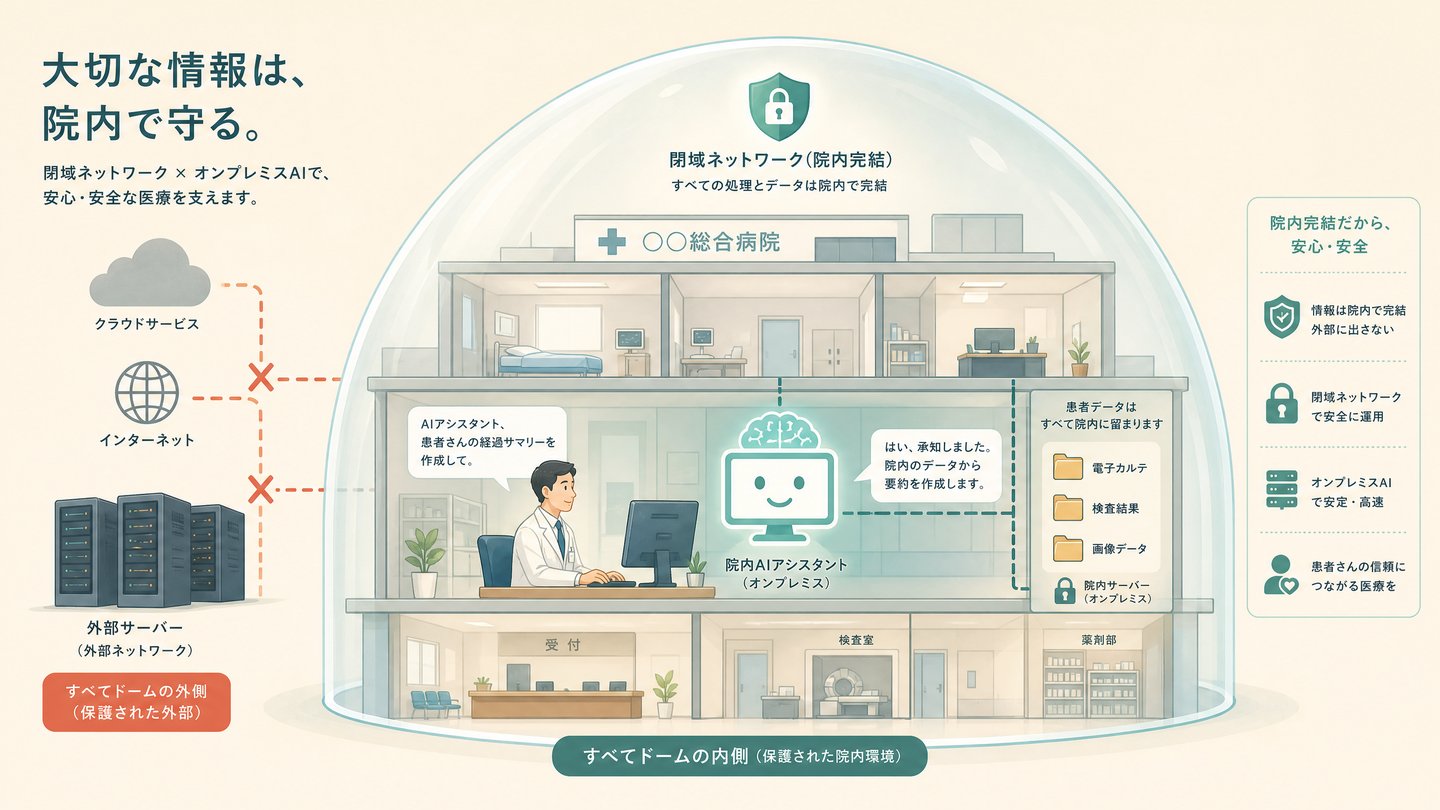
5.2 3省2ガイドラインとの関係
前回記事でも触れましたが、ローカルLLMは3省2ガイドライン(厚労省「医療情報システムの安全管理に関するガイドライン」第6.0版 + 経産省・総務省「医療情報を取り扱う情報システム・サービスの提供事業者における安全管理ガイドライン」第2.0版)の論点の多くを、アーキテクチャレベルで解消します。
データが院外に出ない。外部事業者への委託が発生しない。責任分界点は明確。ローカルLLMは、セキュリティ審査における「そもそも論点が発生しない」選択肢です。
ローカルLLMだからといって全ての要件が自動的に満たされるわけではありません。
ログの保存、アクセス制御、物理的なセキュリティなど、院内システムとして求められる管理体制は別途必要です。
ただし「データが外に出る」というクラウド利用時の最大の障壁が消えることの意味は、非常に大きいです。

5.3 コスト感:結局いくらかかるのか
初期投資の目安を整理します。
| 構成 | 価格帯(日本国内) | 主な用途 |
|---|---|---|
| DGX Spark OEM(MSI等) | 約50〜60万円 | gpt-oss-120b、27B以下モデル |
| DGX Spark Founders Edition | 約65〜70万円 | 上記 + モデルロード高速 |
| DGX Spark × 2台連結 | 約130〜140万円 | 400B級モデル |
| Mac Studio M3 Ultra 256GB | 約85〜90万円 | 全モデル高速動作 |

ランニングコストは電気代のみです。
DGX Sparkの実消費電力は約100W、Mac Studioも同程度。
24時間稼働しても月額の電気代は3,000円程度です。
クラウドAPIの従量課金と比較すると、日常的にAIを活用する場合、6〜12ヶ月で初期投資を回収できる計算になります。
特に複数の部署・スタッフが並行してAIを利用するケースでは、ローカルLLMのコスト優位性が大きくなります。
5.4 現実的な運用構成の提案
医療機関での導入を前提に、目的別の推奨構成を示します。
テキスト業務中心(カルテ要約、文書作成、院内Q&A)
- マシン:DGX Spark OEM(約50〜60万円)
- モデル:Qwen3.5-35B-A3B または gpt-oss-120b
- 総予算:約50〜70万円
マルチモーダル対応(画像含む文書処理、OCR)
- マシン:Mac Studio M3 Ultra 256GB(約85〜90万円)
- モデル:Qwen3.5-27B + Gemma 4 31B(用途に応じて使い分け)
- 総予算:約85〜90万円
最大構成(大規模モデル、複数モデル同時運用)
- マシン:Mac Studio M3 Ultra 256GB
- モデル:gpt-oss-120b + Qwen3.5-35B-A3B を併用
- 総予算:約85〜90万円
6. まとめ

ローカルLLMの導入に必要なものは、「数千万円のサーバー」ではありません。
50〜90万円のデスクトップマシン1台で、医師国家試験の合格基準を超えるAIが、オフライン・閉域環境で動きます。
gpt-oss-120b・Qwen3.5・Gemma 4といった最新のオープンウェイトモデルはいずれもApache 2.0ライセンスで商用利用可能。
マルチモーダル対応や100万トークン超の長文処理など、モデルの進化も加速しています。
簡単な選び方の指針はこうです。
画像も扱うならQwen3.5かGemma 4、テキスト中心ならgpt-oss-120b。
128GBで収まる構成ならDGX Spark、速度や大規模モデルを求めるならMac Studio。
「クラウドか、何も使わないか」の二択ではありません。
閉域でも、十分実用的なAIが手に入る時代です。
GENSHI AIは、ハードウェアの選定からモデルの最適化、院内システムとの連携、運用支援まで、ローカルLLMの導入を一気通貫で支援しています。
ご関心のある方は、お気軽にお問い合わせください。
※本記事の推論速度は、各種ベンチマークレポートおよび筆者の実測値をもとにした目安です。
実際の性能はモデルの量子化方式、コンテキスト長、バッチサイズ、推論フレームワーク、その他のシステム条件によって変動します。
※価格は2026年5月時点の情報です。メモリ供給状況や為替変動により変更される可能性があります。