複雑なレイアウトを持つ医療文書を対象に、複数のOCRモデルの精度を検証しました。テキスト認識精度、構造保持、欠落や誤結合の傾向を比較評価しています。実務活用を見据えたモデル選定・設計検討の参考情報として整理しました。
(GENSHI AI 鈴木貴登)
0. はじめに
OCR(光学文字認識)に関する検証記事は数多く存在しますが、複雑なレイアウトを持つ文書を対象に、実務利用を想定した精度比較を行っている事例は多くありません。
例えば退院サマリーのような医療文書では、行ごとに列数が異なる、セルの幅が不均一、表と文章が混在しているといった「表に近いが、厳密な表構造ではない」レイアウトが頻繁に登場します。このような文書では、単純にテキストが読めるかどうかだけでなく、文書構造をどの程度保ったまま情報を抽出できるかが、実務活用の可否を左右します。
本記事では、こうした複雑なレイアウト文書を対象に、複数のOCRモデルを単体で使用した場合の挙動を比較します。以下を観察し、実験結果として整理しました。
- テキスト認識精度
- レイアウトの保持度
- 情報の欠落や誤結合の傾向
※本検証はあくまで特定条件下での実験的な記録であり、特定の製品やモデルを公式に評価・推奨するものではありません。
1. TL;DR
複雑なレイアウトの医療文書に対しては、claude-opus-4-5-20251101のみが実務利用を現実的に検討できる品質でした。他のモデルでは情報の取りこぼしや構造崩れが多く見られ、安定した実務利用には課題が残る結果となりました。
ただし、文字が大きく構造が単純な文書では差が縮まり、gpt-5.2-2025-12-11なども実用域に入る可能性があります。

2. 実験概要:文書・入力条件・評価方針
2.1 対象文書(3種類)
医療文書に対する実用性評価のため、以下3種類のPDFを用いました。
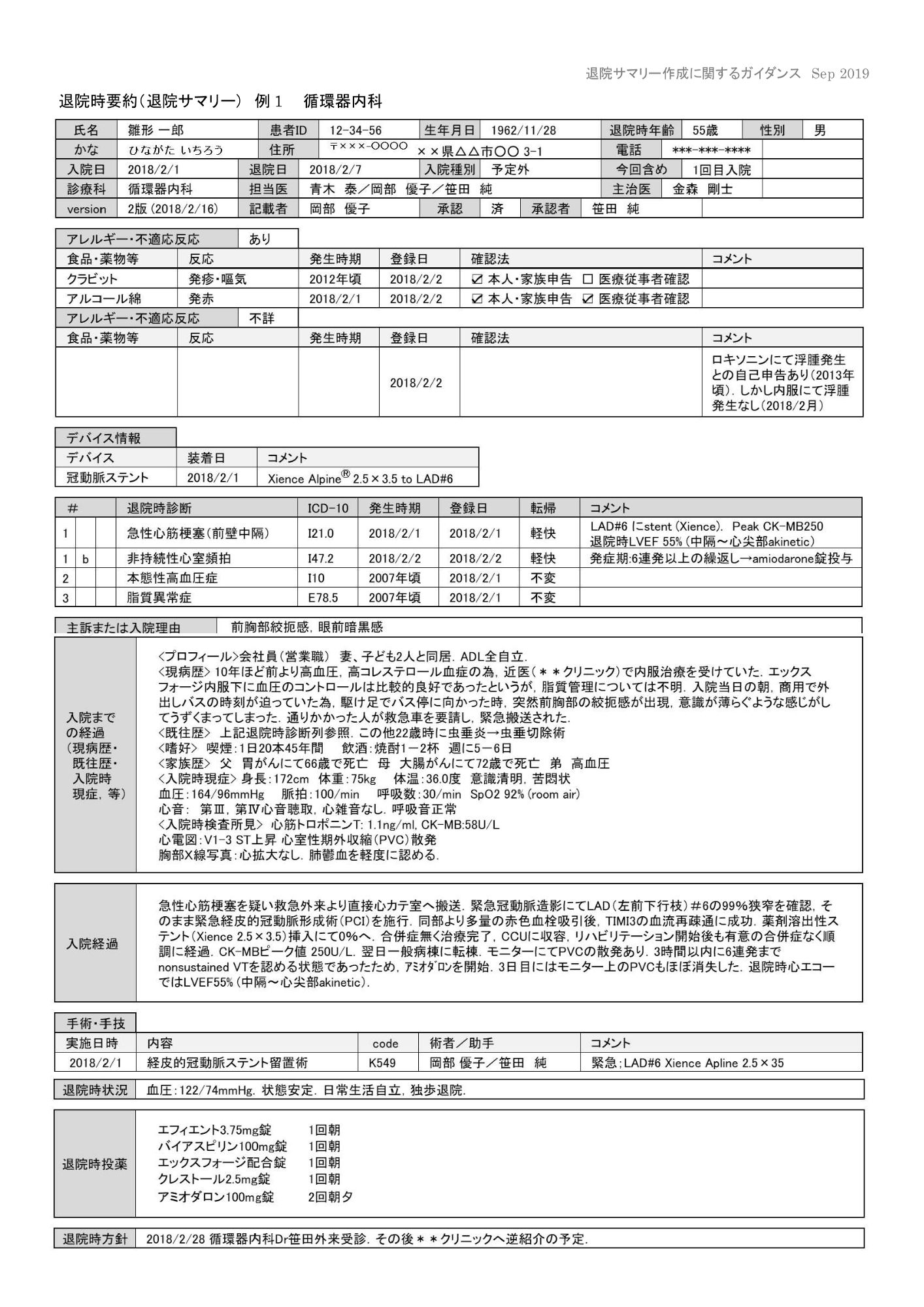
退院サマリー15:ent-summary-15.pdf
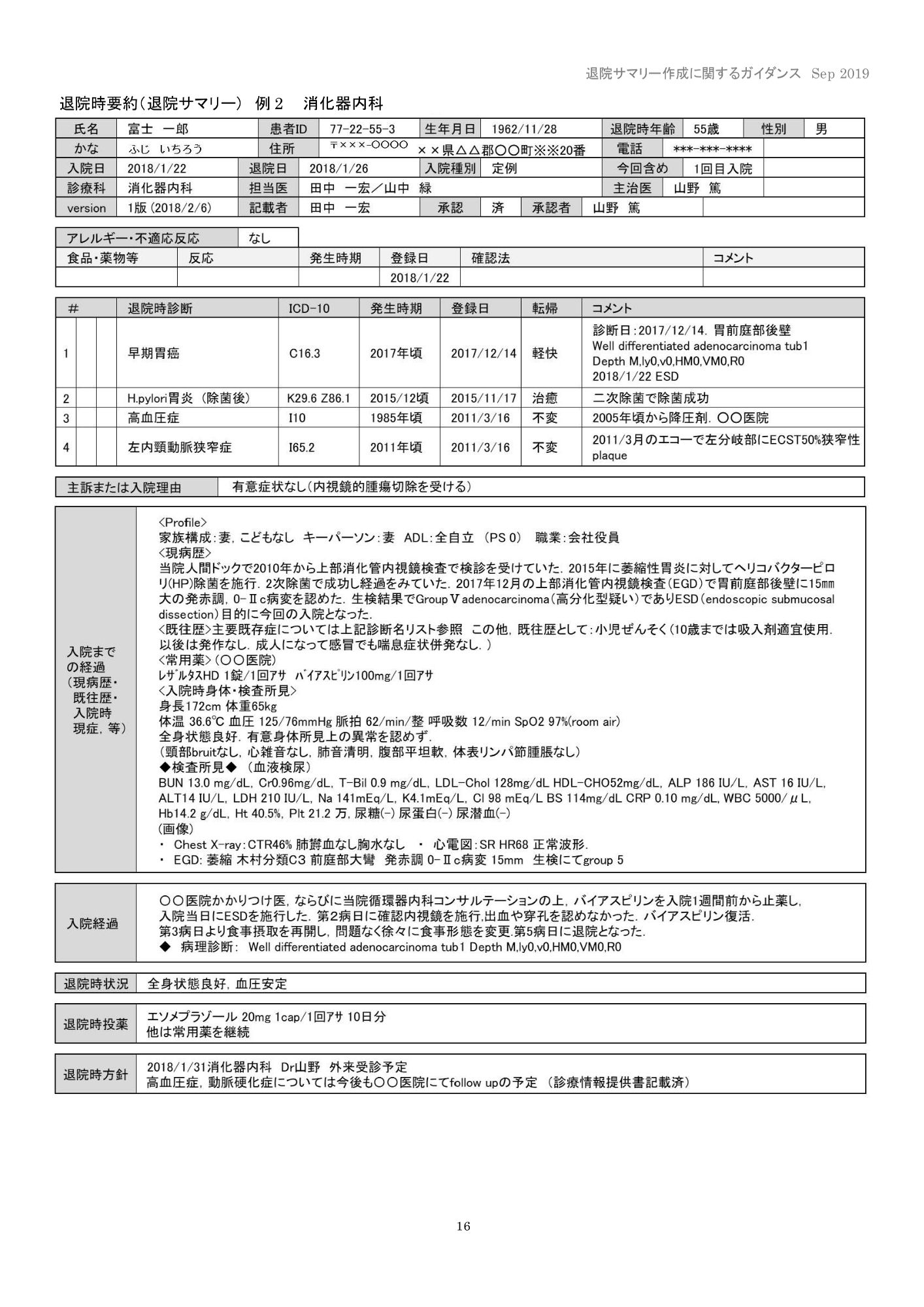
退院サマリー16:ent-summary-16.pdf
紹介状1:referral-letter-1.pdf

それぞれ性質が異なります。
- 退院サマリー15/16:文字サイズが小さい高密度文書
- 紹介状1:文字サイズが比較的大きい低〜中密度文書。紹介状1は検証用途で生成した文書ですが、記載内容に実在の文書形式と異なる表現が含まれていたため、誤解防止の観点から画像全体にモザイク処理を施しています。
また、検証に用いたPDFは厚労省の見本等を利用しました。実際の患者情報は扱っていません。
2.2 入力条件
3種類のPDFをすべて、同一条件(2121px × 3000px)で画像化し、各モデルに入力しました。APIでないもので、大きなモデルはGPUで実行しました。
2.3 評価観点
スプレッドシート上の評価軸は、ざっくり次の5つです。
- 欠落:文書の一部が抜ける
- 挿入:原文にない文言が混ざる
- 構造化理解:表構造・項目対応
- 文字認識/医療用語/数値・記号:固有名詞、薬剤名、ICD-10、I/1混同など
- コスト:APIコスト(円換算目安)
3. 評価対象モデル
本検証で評価した主なモデルは以下です。
ローカル/オープン系・パイプライン
- pp_ocr: https://www.paddleocr.ai/main/en/version3.x/installation.html
- yomitoku: https://kotaro-kinoshita.github.io/yomitoku/installation/
- LightOnOCR-2-1B: https://huggingface.co/lightonai/LightOnOCR-2-1B
- PaddleOCR: https://github.com/PaddlePaddle/PaddleOCR
- Chandra: https://github.com/datalab-to/chandra
- HunyuanOCR: https://github.com/Tencent-Hunyuan/HunyuanOCR
Claude API 系(Anthropic)
- https://claude.com/platform/api
- claude-sonnet-4-5-20250929
- claude-haiku-4-5-20251001
- claude-opus-4-5-20251101
OpenAI API 系
- https://openai.com/ja-JP/api/
- gpt-5-mini-2025-08-07
- gpt-5-nano-2025-08-07
- gpt-5.2-2025-12-11
- gpt-4.1-2025-04-14
Gemini 系(Google)
- https://ai.google.dev/aistudio?hl=ja
- gemini-3-pro-preview
- gemini-3-flash-preview
- gemini-2.5-flash
- gemini-2.5-flash-lite
商用OCR API
- Google Cloud Vision: https://cloud.google.com/vision?hl=ja
- Azure AI Document Intelligence: https://azure.microsoft.com/ja-jp/products/ai-foundry/tools/document-intelligence
- GLM-OCR: https://huggingface.co/zai-org/GLM-OCR
4. 単体モデル比較
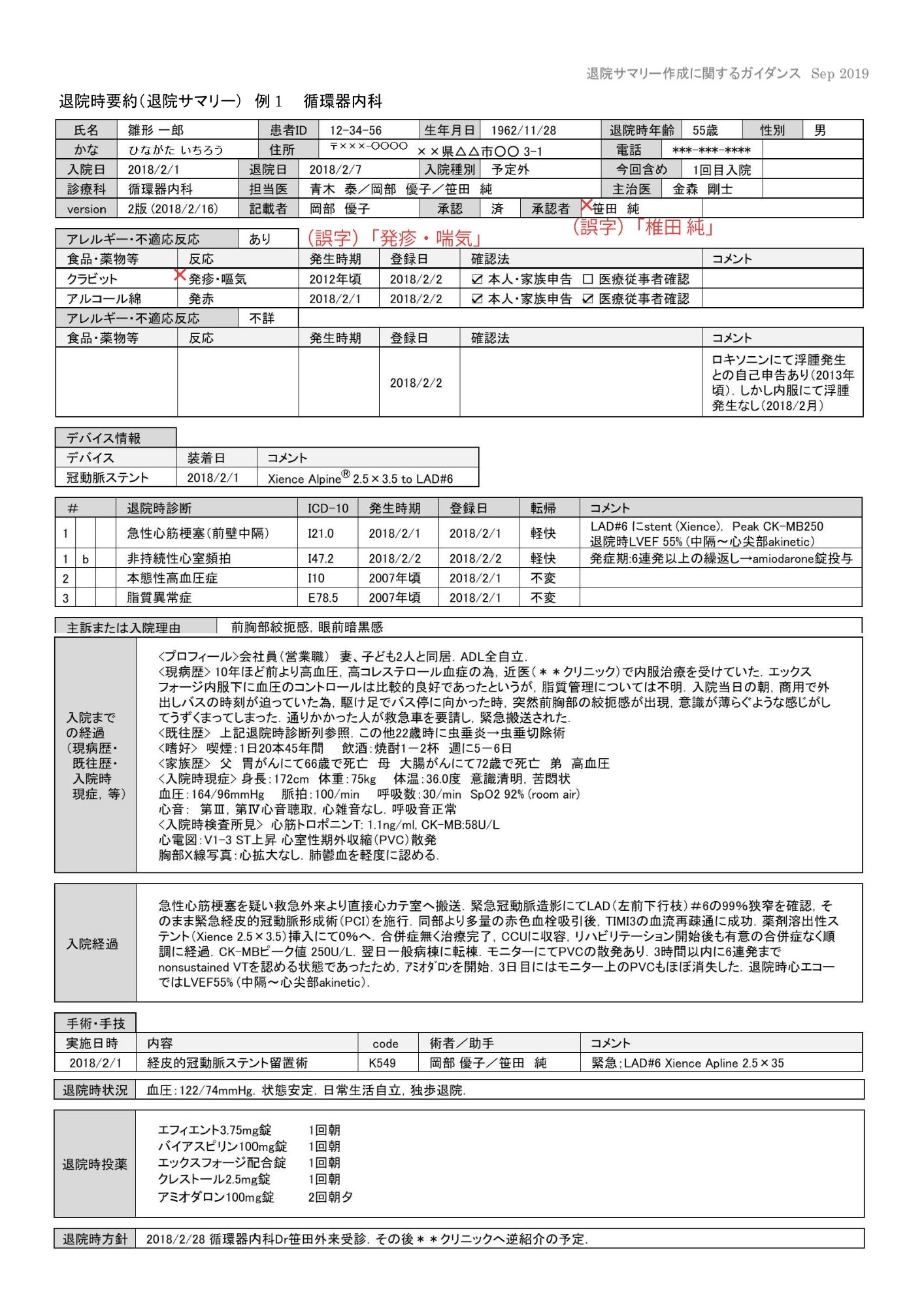
4.1 退院サマリー(ent-summary-15 / 16)
今回のサンプルではかなり明確な傾向が出ました。退院サマリー15/16では、claude-opus-4-5-20251101のみが実用可能と判断しました。他モデルでは以下が顕著でした。
- 誤字・誤変換の多発
- 文書の一部脱落(欠落)
- ハルシネーション(挿入)
- 表構造・項目対応関係の理解不足(構造崩れ)
4.2 紹介状(referral-letter-1)
紹介状1は画像サイズは同じでも文字サイズが大きいため、半数以上のモデルで精度改善が見られました。
- 最も高精度:claude-opus-4-5-20251101
- 次点:gpt-5.2-2025-12-11
ただし他モデルにも軽微な誤字や構造上の不備が残る例があり、運用には注意が必要です。
5. モデル別レビュー
pp_ocr(テキスト認識特化)
複数回試行しても1文字も認識できないという結果でした。少なくとも今回の条件(高密度・複雑レイアウト)では、前処理や設定変更を含めた追加検討が必要です。
yomitoku(パイプライン)
退院サマリーでは、表形式・列数が行ごとに変わる構造に弱い印象でした。医療用語や数値・記号(例:SpO2、ICD-10のI/1)で誤りが出ており、厳密用途では注意が必要です。
一方で紹介状では致命的な破綻は少なく、「構造化は別でやる」前提なら使いどころはありそうです。
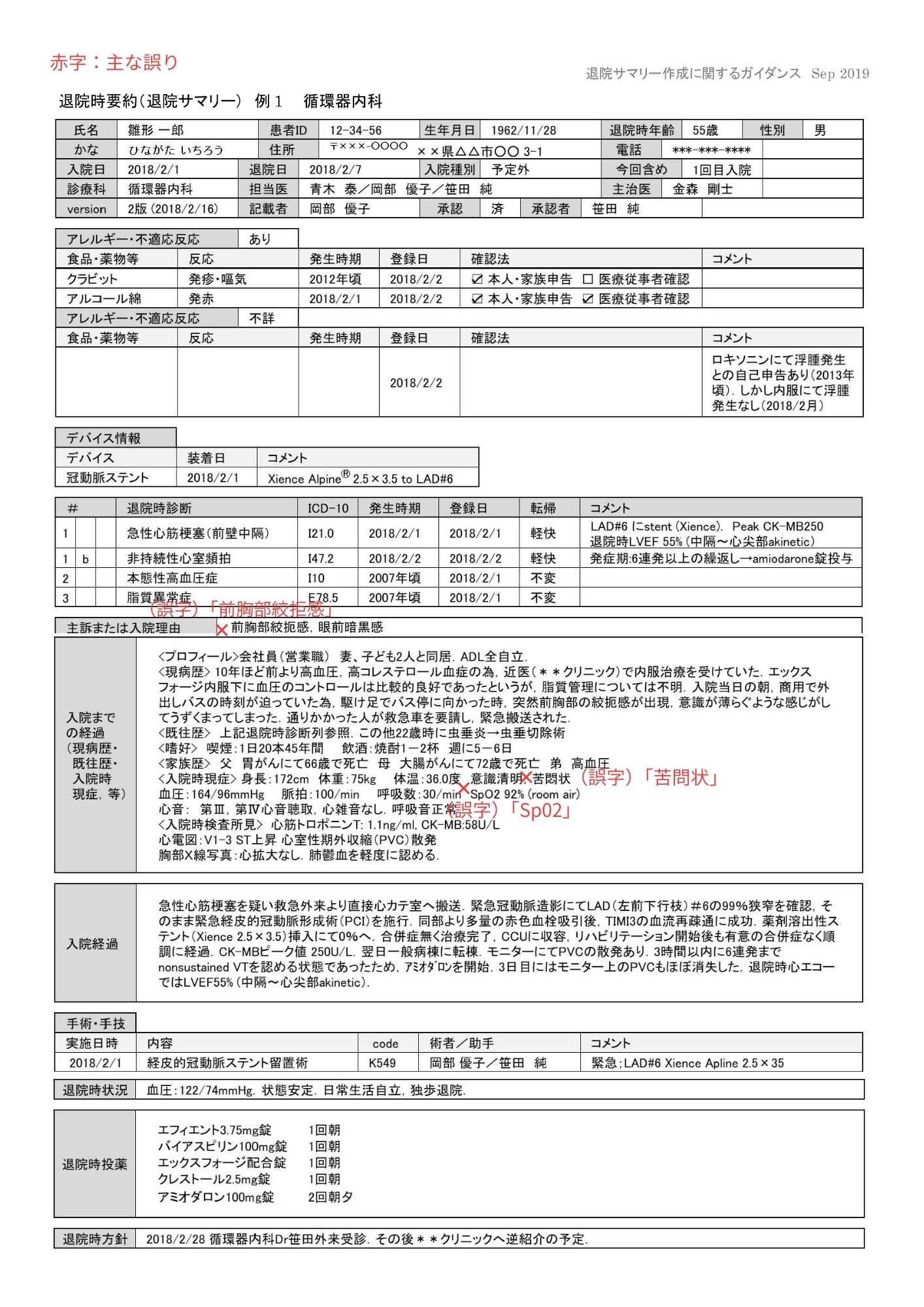
claude-sonnet-4-5-20250929(商用API/Anthropic系)
退院サマリーでは、意味が変わる誤変換や原文にない挿入が目立ち、実運用は難しいと評価しました。人名崩壊や医療用語の取り違えも見られ、検証時点では用途が限定されそうです。
紹介状では一定の安定感はありますが、表記揺れのような軽微な問題は残っています。
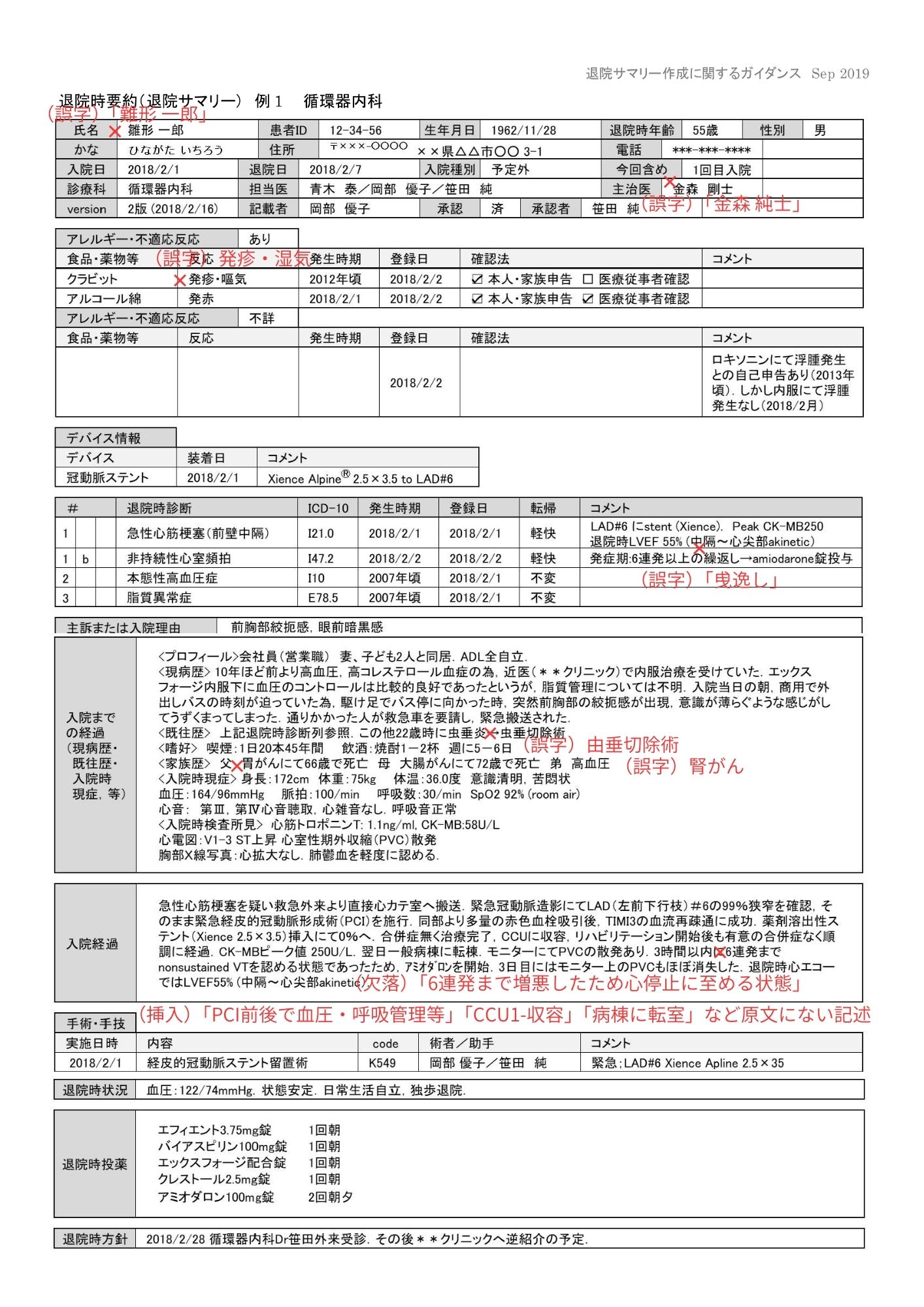
claude-haiku-4-5-20251001(商用API)
退院サマリーでは、誤字が頻発し、氏名や医療用語が崩れやすい結果でした。構造自体の分解はある程度できても、文字認識の土台が崩れると後段の修正では担保しづらい、という印象です。
一方で紹介状では文字サイズが十分ある条件だと大きな破綻が減る可能性があります。
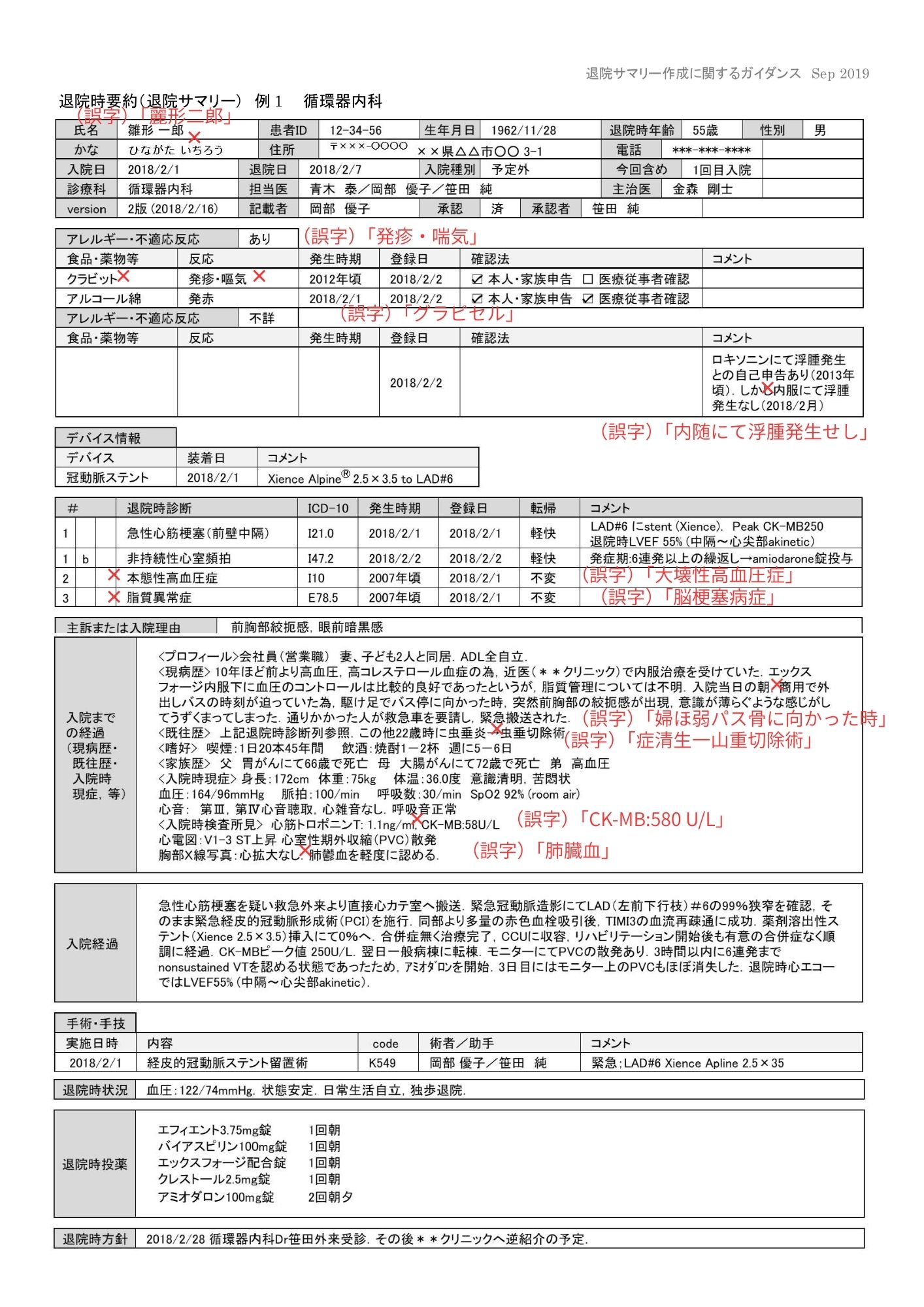
claude-opus-4-5-20251101(商用API)
退院サマリー15/16では全文保持と構造の安定性が最も高い結果でした。紹介状では目立つ不備が見つからない水準でした。
gpt-5-mini-2025-08-07(商用API/OpenAI系)
退院サマリー15/16で大部分が欠落し、比較的厳しい結果でした。紹介状では、他モデルと比べると精度が落ち、チェックボックス扱いなどで不備が見られます。
gpt-5-nano-2025-08-07(商用API)
退院サマリー15/16では欠落が大きい/画像を一切読み取れていないという評価でした。紹介状でも出力なしで、今回の条件ではOCR用途として成立しませんでした。軽量モデルの強み以前に、タスク適合性の再検討が必要です。
gpt-5.2-2025-12-11(商用API)
退院サマリー15では誤認・欠落・不要タグなどがあり、純OCRとしては弱さが出ました。一方、退院サマリー16では相対的に改善が見られ、文字サイズや密度に左右される印象があります。紹介状では不備が見当たらない水準だったため、低〜中密度文書では有力候補になり得ると思われます。
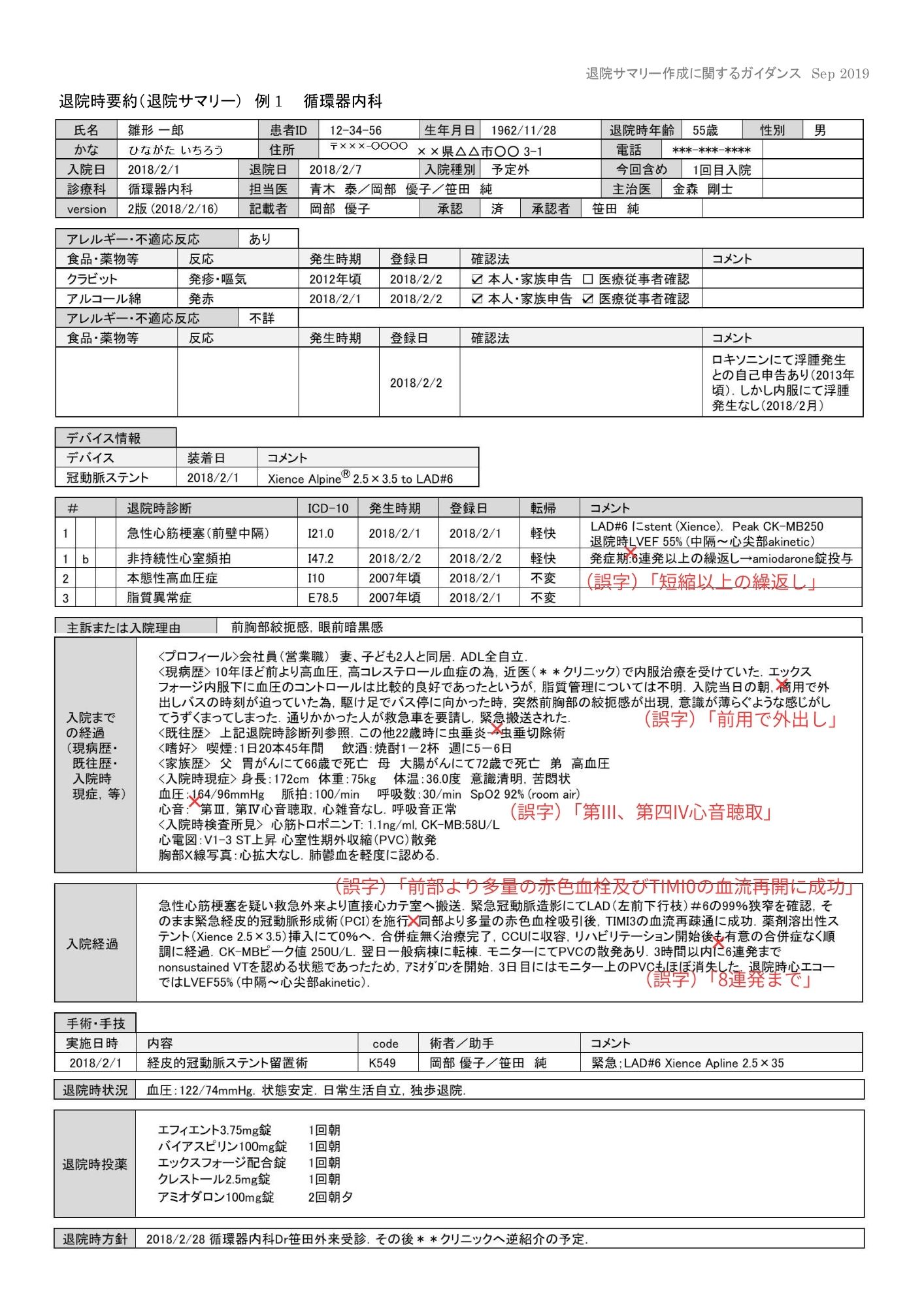
gpt-4.1-2025-04-14(商用API)
退院サマリー15では、ハルシネーションや医療用語の誤りが致命的という評価でした。退院サマリー16でもタグ不整合・誤字などがあり、構造化前提だと後段処理が難しくなります。
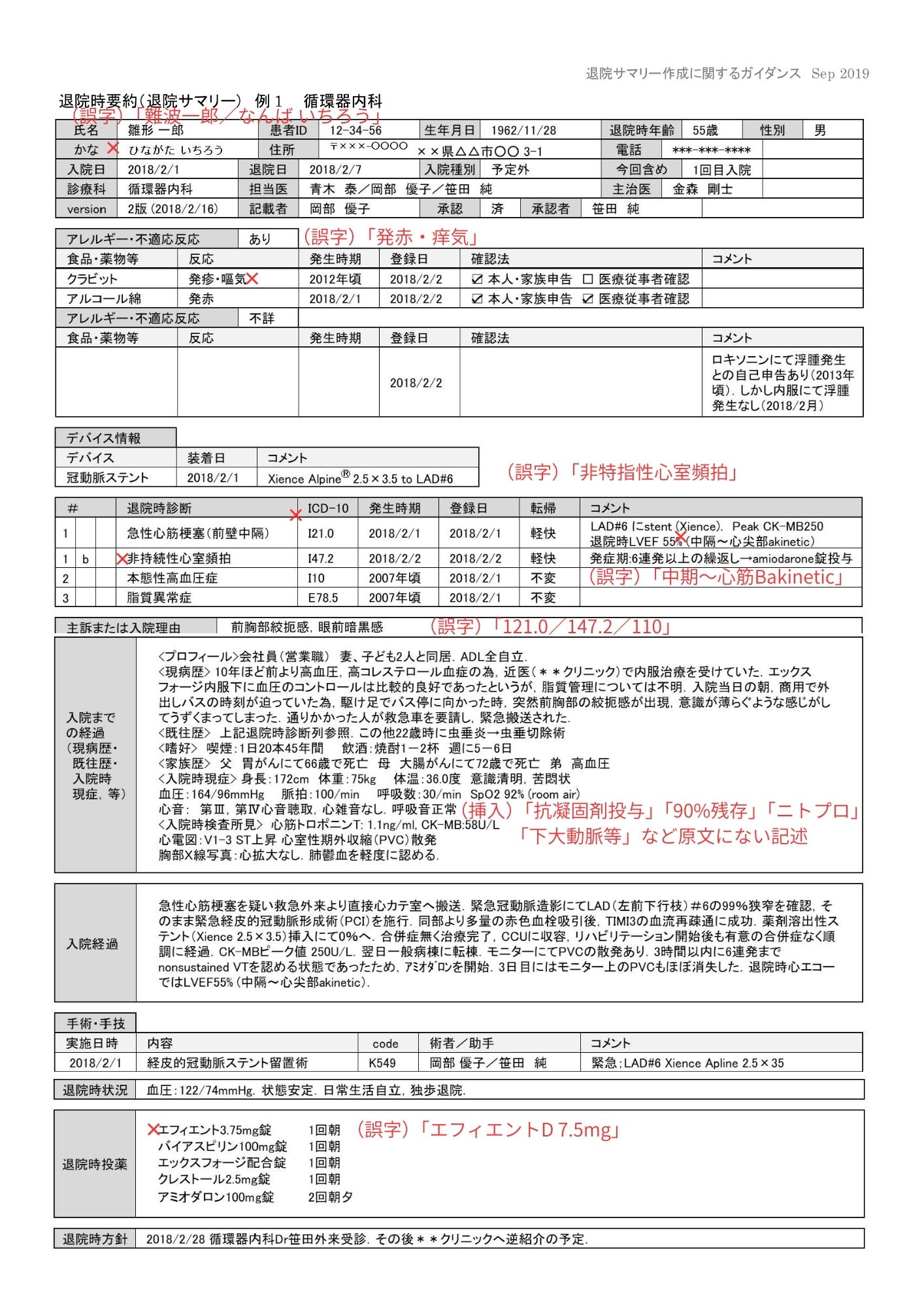
gemini-3-pro-preview(商用API)
今回の退院サマリー15では、APIタイムアウトで実行できないという結果でした。精度以前に実行安定性が論点になり、検証を継続するにはリトライ設計やタイムアウト設定の調整が必要です。少なくとも本記事では、同一条件での比較が成立しないため、評価対象としては保留扱いにしています。
gemini-3-flash-preview(商用API)
退院サマリー15/16、紹介状いずれも出力なし/大規模な欠落が目立ちました。複雑文書の全文保持という観点では、今回の条件では厳しい結果です。短文抽出など別タスクなら可能性はありますが、本検証の目的(全文OCR+構造)とはズレがありそうです。
gemini-2.5-flash(商用API)
退院サマリー15/16、紹介状ともに大規模欠落が中心で、OCR用途としては厳しい評価になりました。欠落があると、後段での補完は基本的に原文参照が必要になり、業務フロー上の負担になります。
gemini-2.5-flash-lite(商用API)
退院サマリーでは、タグの意味が崩れる/タグ構造が壊れるなど、構造化理解が弱い評価でした。一方で紹介状では不備が少なく、文字が大きい・構造が単純な条件なら実用域に寄る可能性があります。
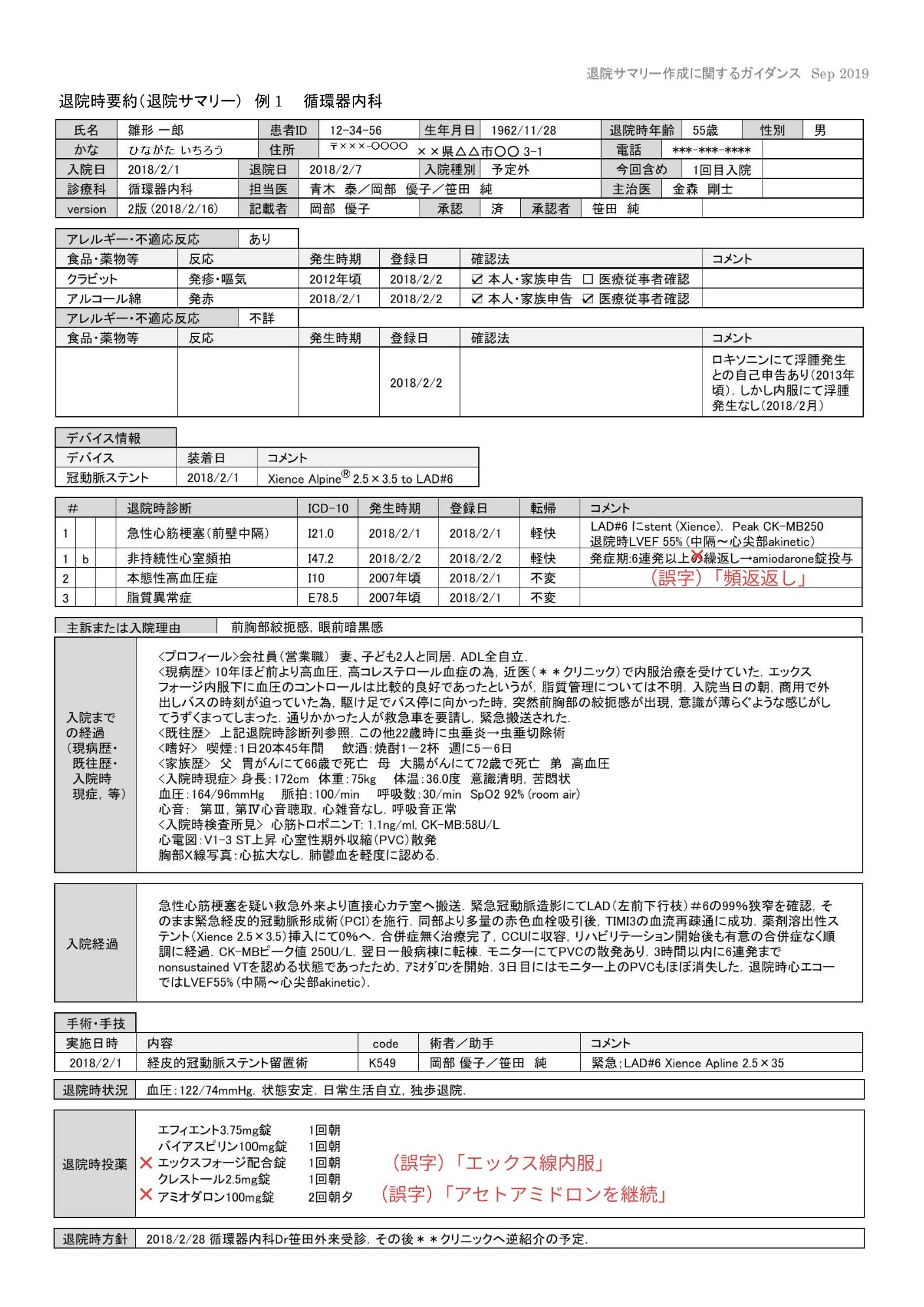
LightOnOCR-2-1B(VLMベース)
退院サマリーでは、構造自体は大崩れしない一方で、人名と医療用語の誤字がネックになりました。紹介状でも誤字が複数あり、専門用語が混ざる現場文書ではチェック工程が残りそうです。
PaddleOCR(VLMベース)
退院サマリー15では「暗号のような出力」、退院サマリー16では構造化ができず誤字もあり、評価は厳しめでした。紹介状では、医学用語以外の文字はそこそこ読める一方、タグ構造が正常に出ない点が課題です。構造化を別方式で担うなら可能性はありますが、本検証の前提であるタグ構造とは噛み合いにくい結果でした。
Chandra(VLMベース/GPU実行含む)
退院サマリー15は大規模欠落、16は空ファイル、紹介状も空ファイルで、今回は安定して出力を得られませんでした。GPU実行できても、出力が継続しないと比較評価が難しいため、まずは実行条件の再現性確保が先になります。本記事では「検証条件下で比較困難」として扱います。
HunyuanOCR(VLMベース/GPU実行含む)
退院サマリー15は白紙出力、16は冒頭で出力が途絶、紹介状は空ファイルで、今回の条件では結果を得られず、モデルを評価できない状態でした。
Google Cloud Vision(テキスト認識特化/商用OCR API)
退院サマリー15/16・紹介状いずれでも、文字認識単体は高い一方で、構造化で崩れやすいという結果でした。医療用語を拾えている例もあり、ベースOCRとしての強さが見えます。
Azure AI Document Intelligence(Microsoft系)
退院サマリーでは、チェックボックスや一部漢字・記号が弱く、構造化タグ出力も不十分という評価でした。一方で文字認識自体は一定の水準があり、後処理次第で可能性はある、という整理もできます。紹介状でも構造タグが出ない/順番の前後などがあり、本記事の「タグ構造で比較」前提とは相性が良くありませんでした。
GLM-OCR(VLMベース/マルチモーダルOCR)
退院サマリー15ではAPIタイムアウトにより実行できませんでした。文字サイズの大きい紹介状では、不備はほぼ見られませんでした。
7. まとめ
本記事では、複雑なレイアウトを持つ日本語文書を対象に、API前提でOCRモデルを比較した実験記録を整理しました。今回のサンプルでは、高密度文書(退院サマリー)においてはclaude-opus-4-5-20251101が最も安定する傾向が見られました。一方、文字サイズが十分に確保された文書(紹介状)では、複数のモデルで精度が改善し、gpt-5.2も実用的となるケースが確認できました。
なお、本検証は技術的なOCR精度と挙動の比較に主眼を置いたものであり、医療情報システムにおける運用要件や、いわゆる「3省2ガイドライン」に基づくセキュリティ・体制面の検討は対象としていません。これらは医療分野で実際にシステムを導入・運用する際には重要な観点であり、本記事の結果を適用する場合には、別途整理・検討が必要となります。
その前提の上で、本記事が複雑なレイアウト文書を構造化して扱うOCRモデル選定や設計を検討する際の参考情報となれば幸いです。
8. 最後に
GENSHI AIでは、医療分野に限らず、OCRをはじめとするAI技術の実務導入・運用についての知見を蓄積しています。文書構造化やデータ活用に関する課題をお持ちでしたら、ぜひお気軽にご相談ください。
また、GENSHI AIでは一緒に働く仲間を募集しています。AI技術を活用したプロダクト開発や実務課題の解決に興味のある方は、ぜひお声がけください。